Minimum spanning trees¶
Consider a connected, undirected, and edge-weighted graph \( \Graph = \Tuple{\Verts,\Edges,\UWeights} \). A spanning tree of \( \Graph \) is a connected acyclic graph \( T = \Tuple{\Verts,\MSTCand,\UWeights} \) with \( \MSTCand \subseteq \Edges \). Its weight is the sum of its edge weights \( \sum_{\Set{u,v} \in \MSTCand}\UWeight{u}{v} \). A spanning tree of \( \Graph \) is a minimum spanning tree (MST) of \( \Graph \) if its weight is the smallest among all spanning trees of \( \Graph \). Observe that a graph can have many minimum spanning trees.
Example
Consider the graph shown below.
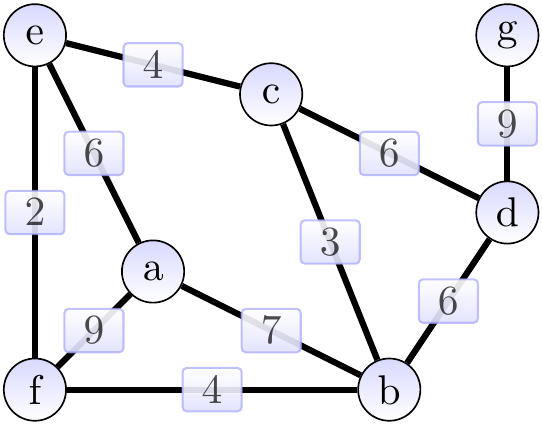
The highlighted edges in the two graphs below show two spanning trees for the graph above. The first one has weight 31 and is not minimum. The second one is a minimum spanning tree with weight 30.
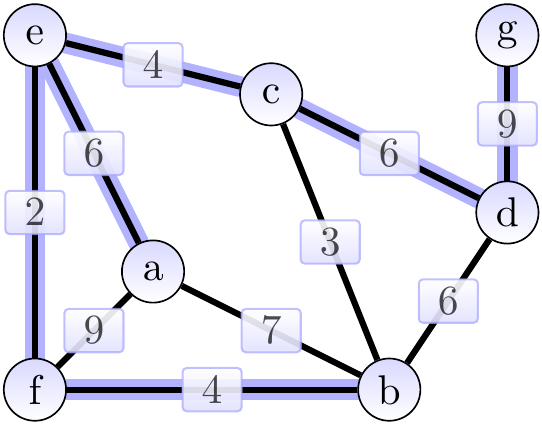
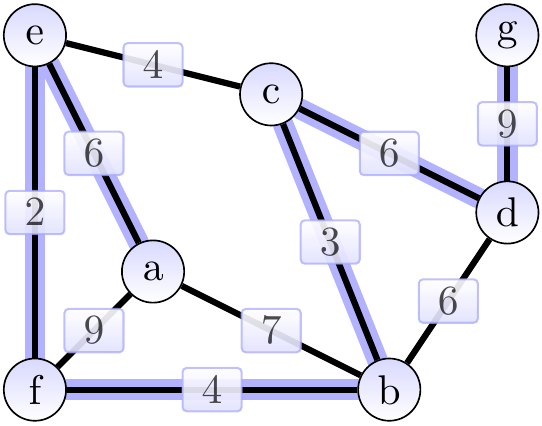
As an application example, if the graph models an electronic circuit board so that
the vertices are the components and
the edges are the possible routes for the power/clock wires between the components,
then a minimum spanning tree of the graph gives a way to connect all the components with the power/clock wire by using the minimum amount of wire.
Note that we only consider connected graphs: for graphs with many components, we could compute a minimum spanning trees for each component individually. And we only consider edge-weighted undirected graphs; for directed graphs the analog concept is called “spanning arborescence of minimum weight” or “optimal branching”, see, for instance, the Wikipedia page on Edmond’s algorithm. These are not included in the course.
A generic greedy approach¶
Given a graph, it may have an exponential amount of spanning trees. Thus enumerating over all of them in order to find a minimum one is not a feasible solution. But there are very fast algorithms solving the problem:
Kruskal’s algorithm
Prim’s algorithm
Both are greedy algorithms (recall Section Greedy Algorithms). They build an MST by starting from an empty set and then adding edges greedily one-by-one until the edge set is a tree spanning the whole graph. During the construction of this edge set, call it \( \MSTCand \), both maintain the following invariant:
Before each iteration of the main loop, \( \MSTCand \) is a subset of some MST.
To maintain the invariant, the algorithms then select and add a safe edge for \( \MSTCand \): an edge \( \Set{u,v} \notin \MSTCand \) such that \( \MSTCand \cup \Set{\Set{u,v}} \) is also a subset of some MST. Such an edge always exists until \( \MSTCand \) is an MST: as \( \MSTCand \) is a subset of some MST, then there is an edge in that MST but not in \( \MSTCand \) and we can add it to \( \MSTCand \). The greedy heuristics are used to select such a safe edge efficiently. The generic version in pseudo-code:
We now only need a way to efficiently detect safe edges. For that, we use the following definitions:
A cut for a graph \( \Graph = \Tuple{\Verts,\Edges,\Weights} \) is a partition \( \Tuple{S,\Verts \setminus S} \) of \( \Verts \).
An edge crosses a cut \( \Tuple{S,\Verts \setminus S} \) if its other endpoint is in \( S \) and other in \( \Verts \setminus S \).
An edge is a light edge crossing a cut if its weight is the smallest among those edges that cross the cut.
Example
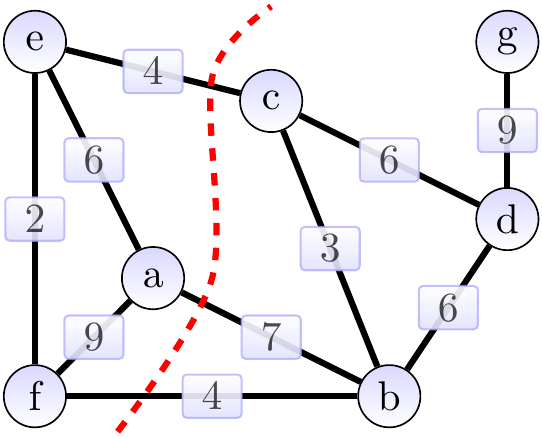
Consider the graph below. The cut \( \Tuple{\Set{a,e,f},\Set{b,c,d,g}} \) is shown with a dashed red line. The edges \( \Set{a,b} \), \( \Set{b,f} \) and \( \Set{c,e} \) cross the cut. The light edges crossing the cut are \( \Set{b,f} \) and \( \Set{c,e} \).
The following theorem gives an easy method for the greedy algorithms to select the next safe edge to be included in the MST under construction. Essentially, it says that for any cut that doesn’t split the partial MST under construction, one can choose any crossing edge with the smallest weight to be included in the MST. We need one more definition: a cut \( \Tuple{S,\Verts \setminus S} \) respects a set \( \MSTCand \subseteq \Edges \) of edges if no edge in \( \MSTCand \) crosses the cut.
Theorem
Let \( \Graph = \Tuple{\Verts,\Edges,\Weights} \) be an undirected, connected edge-weighted graph. If \( \MSTCand \) is a subset of an MST for \( \Graph \), \( \Tuple{S,\Verts \setminus S} \) is a cut for \( \Graph \) that respects \( \MSTCand \) and \( \Set{u,v} \) is a light edge crossing \( \Tuple{S,\Verts \setminus S} \), then \( \Set{u,v} \) is a safe edge for \( \MSTCand \).
Example
Again, consider the graph below. The cut \( \Tuple{\Set{a,e,f},\Set{b,c,d,g}} \) is shown with a dashed red line. The edges \( \Set{a,b} \), \( \Set{b,f} \) and \( \Set{c,e} \) cross the cut.
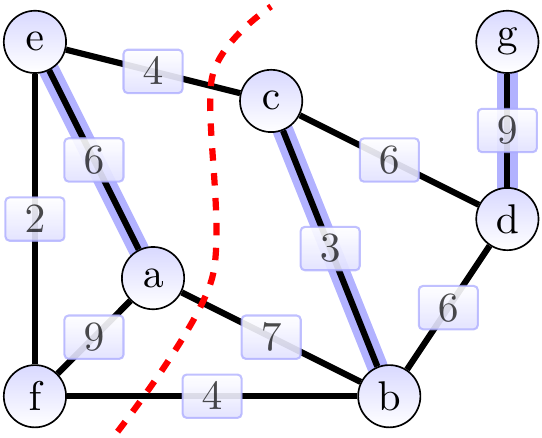
The light edges crossing the cut are \( \Set{b,f} \) and \( \Set{c,e} \). The edges in \( \MSTCand \), the MST under construction, are highlighted. They are a subset of an MST. The cut respects \( \MSTCand \). By the theorem, either of the light edges can be added to \( \MSTCand \) so that the result is still a subset of an MST.
Proof (Sketch)
Let \( \MSTCand’ \) be the edge set of any MST \( T’ \) such that \( \MSTCand \subset \MSTCand’ \) holds.
If \( \Set{u,v} \in \MSTCand’ \), then it is safe for \( \MSTCand \) and we are done.
Suppose that \( \Set{u,v} \notin \MSTCand’ \), \( u \in S \), and \( v \in \Verts \setminus S \). In the MST \( T’ \) there is a unique simple path from \( u \) to \( v \) as it is a tree. Let \( y \) be the first vertex in this path that belongs to the set \( \Verts \setminus S \) and let \( x \) be its predecessor in the path still belonging to the set \( S \). The edge \( \Set{x,y} \) does not belong to the set \( \MSTCand \) as the cut respects the edge set. As the edge \( \Set{u,v} \) is a light edge crossing the cut, it holds that \( \UWeight{u}{v} \le \UWeight{x}{y} \) as also \( \Set{x,y} \) crosses the cut. Consider the tree \( T \) obtained by first removing the edge \( \Set{x,y} \) from the tree \( T’ \) (this results in two disjoint trees, other including the vertex \( u \) and the other the vertex \( v \)) and then adding the edge \( \Set{u,v} \). The weight of this tree \( T \) is at most the weight of the tree \( T’ \); as \( T’ \) is minimal, also \( T \) is and thus the edge \( \Set{u,v} \) is safe for \( \MSTCand \).
Kruskal’s algorithm¶
Kruskal’s algorithm finds the next safe edge to be added by
first sorting the edges in non-decreasing order by their weight, and
then finding the smallest-weight edge that connects two trees in the current edge set \( \MSTCand \).
To quickly detect whether an edge connects two trees, the vertices in the trees are maintained in a disjoint-sets data structure (recall Section Disjoint-sets with the union-find data structure). When an edge is added, the trees in question merge into a new larger tree. The cut is not explicitly maintained but for an edge \( \Set{u,v} \) connecting two trees involving \( u \) and \( v \) respectively, one can take any cut that puts the tree of \( u \) on one side and the tree of \( v \) to the other. The possible other trees are put on either side.
In pseudo-code:
With the rank-based disjoint-sets implementation introduced in Section Disjoint-sets with the union-find data structure, one can argue that the worst-case running time of the algorithm is \( \Oh{\NofE \Lg{\NofE}} \) — sorting the edges takes asymptotically the largest amount of time in the algorithm. Recalling that \( \NofE \le \NofV^2 \) and thus \( \Lg{\NofE} \le 2 \Lg{\NofV} \), the worst-case bound can be stated also as \( \Oh{\NofE \Lg{\NofV}} \).
Example: Applying Kruskal’s algorithm
Consider the graph shown below. The edges in a weight-sorted order are (edges with the same weight are ordered arbitrarily): \( \Set{e,f}, \Set{b,c}, \Set{b,f}, \Set{c,e}, \Set{c,d}, \Set{a,e}, \Set{b,d}, \Set{a,b}, \Set{a,f}, \Set{d,g} \).
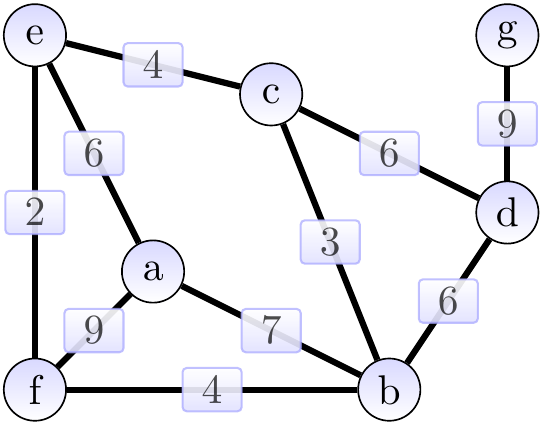
First, we add the edge \( \Set{e,f} \) of weight 2 and obtain the situation below (the edges in the MST under construction \( \MSTCand \) are highlighted). The cut considered could be \( \Tuple{\Set{e},\Set{a,b,c,d,f,g}} \).
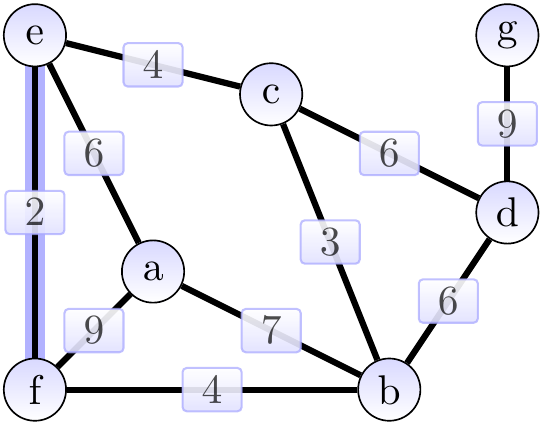
Next, we add the edge \( \Set{b,c} \) of weight 3 and obtain the situation below. The cut considered could be \( \Tuple{\Set{b},\Set{a,c,d,e,f,g}} \).
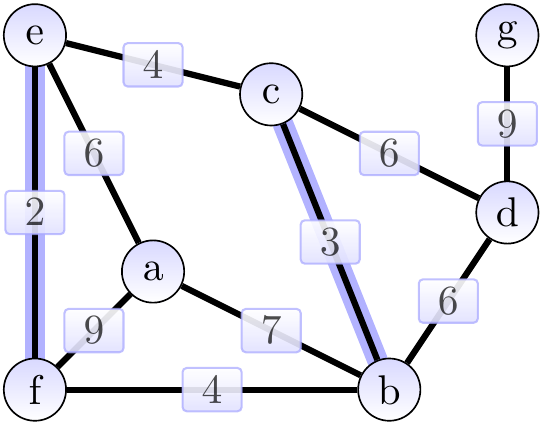
Next, we add the edge \( \Set{b,f} \) of weight 4 and obtain the situation below. The cut considered could be \( \Tuple{\Set{e,f},\Set{a,b,c,d,g}} \).
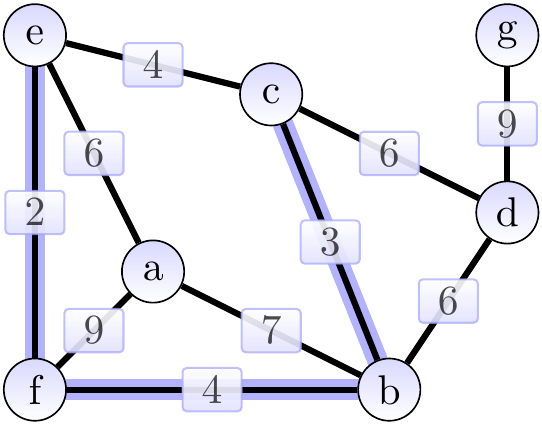
The next edge \( \Set{c,e} \) is skipped because the vertices \( c \) and \( e \) already belong to the same tree. After this, we add the edge \( \Set{c,d} \) of weight 6 and obtain the situation below. The cut considered could be \( \Tuple{\Set{b,c,e,f},\Set{a,d,g}} \).
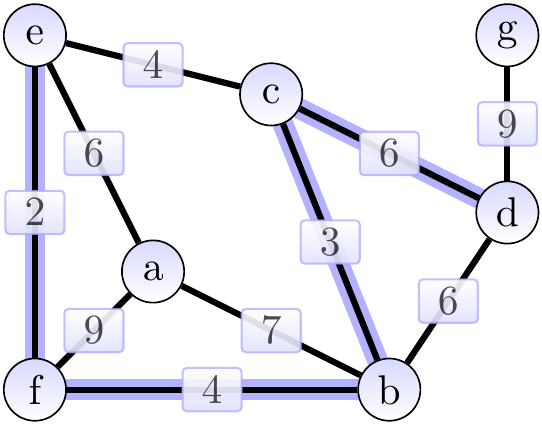
Next, we add the edge \( \Set{a,e} \) of weight 6 and obtain the situation below. The cut considered could be \( \Tuple{\Set{a},\Set{b,c,d,e,f,g}} \).
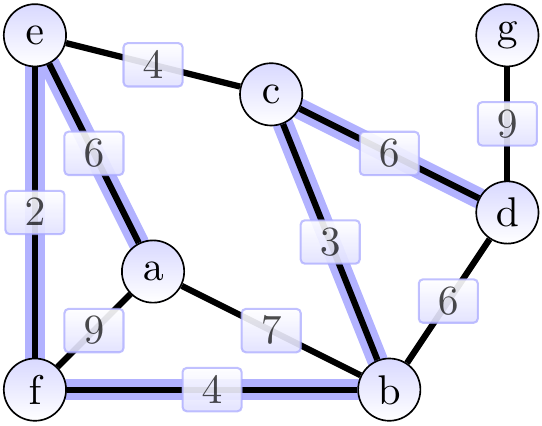
The next edges \( \Set{b,d} \), \( \Set{a,b} \), and \( \Set{a,f} \) are skipped because their end-points already belong to the same tree. Finally, we add the edge \( \Set{d,g} \) of weight 9 and obtain the situation below. The cut considered could be \( \Tuple{\Set{a,b,c,d,e,f},\Set{g}} \).
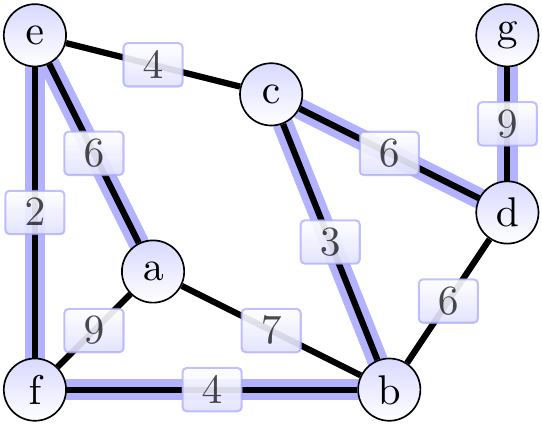
The result shown above is an MST of weight 30.
Prim’s algorithm¶
Prim’s algorithm also implements the generic greedy MST finding algorithm but selects the next safe edge in a different way. It maintains the cut explicitly:
on the other half is the whole MST constructed so far, while
the other half are the vertices not yet joined to the MST.
The process starts from an arbitrary root vertex. Then, at each step, an arbitrary light edge from the first half to the second half is selected and thus one vertex is moved from the second half to the first. To select a light edge quickly, each vertex in the second half maintains, as attributes, the weight (referred to as “key” in the pseudo-code) and the other end of a smallest weight edge (“parent” in the pseudo-code) coming to it from the first half. All the vertices in the second half are stored in a minimum priority queue \( Q \) (recall Section Priority queues with binary heaps) with the weight acting as the priority key. In this way, it is efficient to find the vertex with the smallest key: the edge from the first half to it must thus be a light edge. In the beginning, all the weights are \( \infty \) except for the root vertex which has weight 0. Whenever a vertex is moved from the second half to the first (dequeued from the priority queue), its neighbors’ attributes are updated.
In pseudo-code:
Example: Applying Prim’s algorithm
Consider again the graph shown below.
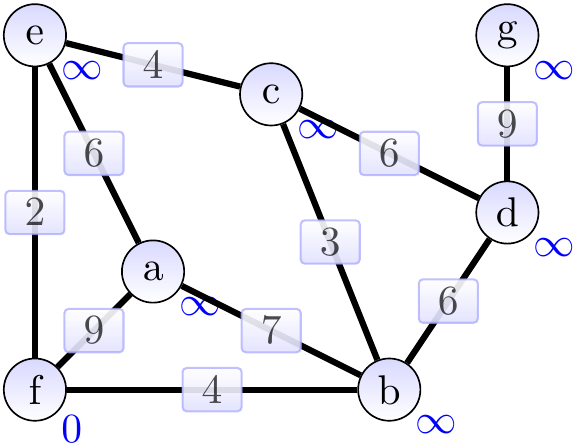
The graphs below show the constructed spanning tree (the highlighted edges) at the end of each while-loop execution, green vertices are the ones not in \( Q \). Supposing that the root vertex was \( f \), the situation after the first iteration is shown below. Observe that the weights of the neighbors of \( f \) have been updated. The “parent” attributes are not shown in the graph.
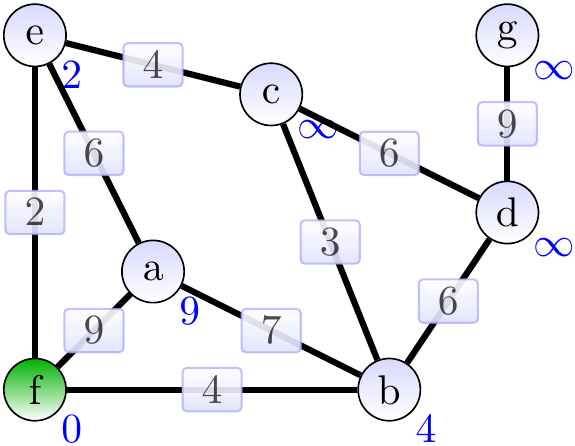
Next, the vertex \( e \) with the lowest priority and the edge \( \Set{e,f} \) are added to the MST. The weights of the neighbors of \( e \) are updated.
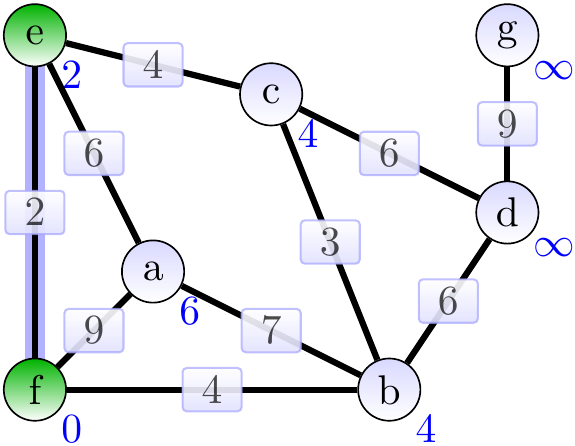
Now the edge \( \Set{b,f} \) is added to the MST. Observe that the edge \( \Set{c,e} \) could have been selected instead and this would result in a different final MST.
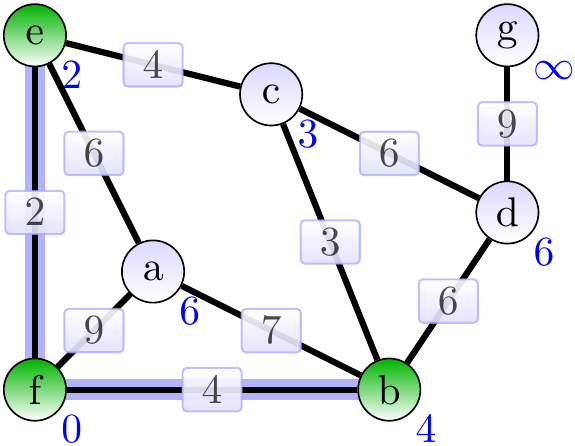
Next, add the edge \( \Set{b,c} \).
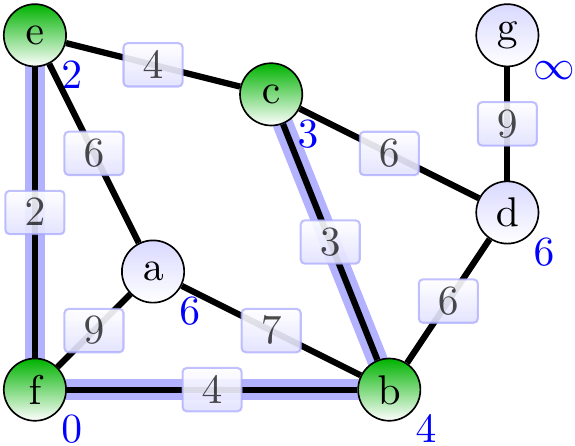
Next, add the adage \( \Set{b,d} \).
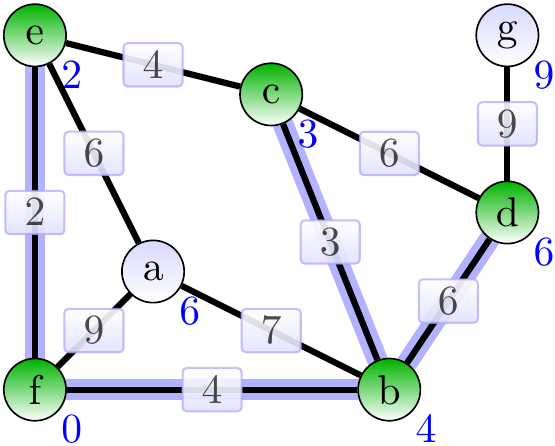
Next, add the age \( \Set{a,e} \).
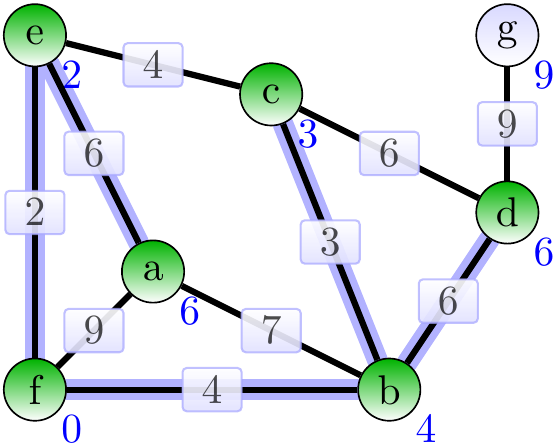
Next, add the age \( \Set{d,g} \).
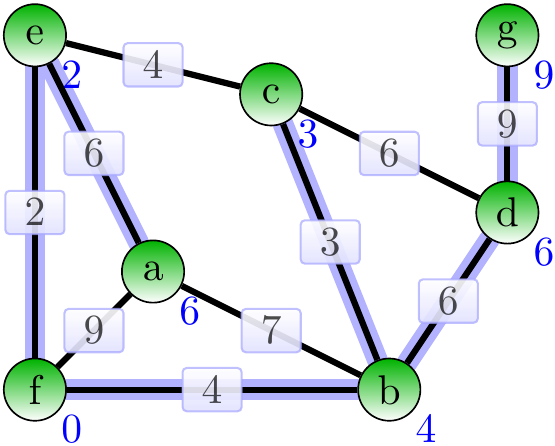
The final result is an MST of wight 30.
Let’s perform a worst-case running time analysis of the algorithm. Assume that priority queues are are implemented with heaps (recall Section Priority queues with binary heaps).
The initialization phase, including the priority queue initialization, can be done in \( \Oh{\NofV \Lg{\NofV}} \). It is quite easy to see that in this case it is easy to initialize the priority queue in linear time as well and thus the initialization phase can in fact be done in time \( \Oh{\NofV} \).
The while-loop executes \( \NofV \) times as one vertex is removed from \( Q \) in each iteration.
Removing a smallest element from the priority queue takes time \( \Oh{\Lg{\NofV}} \)
The set \( \MSTCand \) can be implemented as a linked list or an array of \( \NofV-1 \) elements and thus adding an edge to it takes constant time.
Each edge is considered twice, once for each end point
The keys of the vertices are thus updates at most \( 2 \NofE \) times, each update taking \( \Oh{\Lg{\NofV}} \) time.
The total running time is thus \( \Oh{\NofV + \NofV \Lg{\NofV} + \NofE\Lg{\NofV}} \). This equals to $$\Oh{\NofE\Lg{\NofV}}$$ as \( \NofE \ge \NofV - 1 \) for connected graphs.
A small side track: Steiner trees¶
As shown above, we have very efficient algorithms for finding minimum spanning trees. But if we make a rather small modification in the problem definition, we obtain a problem for which we do not know any polynomial time algorithms at the moment. In fact, many believe (but we cannot yet prove this) that such algorithms do not exist. Consider the problem of finding minimum Steiner trees instead of minimum spanning trees.
Definition: Minimum Steiner tree problem
Given a connected, edge-weighted undirected graph \( \Graph=\Tuple{\Verts,\Edges,\UWeights} \) and a subset \( S \subseteq \Verts \) of terminal vertices, find an acyclic sub-graph \( \Graph=\Tuple{\Verts,\MSTCand,\Weights} \) with \( \MSTCand \subseteq \Edges \) that (i) connects all the terminal vertices to each other with some paths and (ii) minimizes the edge-weight sum \( \sum_{\Set{u,v}\in\MSTCand}\UWeight{u}{w} \).
That is, the tree does not have to span all the vertices but only the terminals and some of the other needed to connect the terminals to each other.
Example
Consider the graph on the left below with the terminal vertices \( \Set{a,b,h,k} \) shown in green.
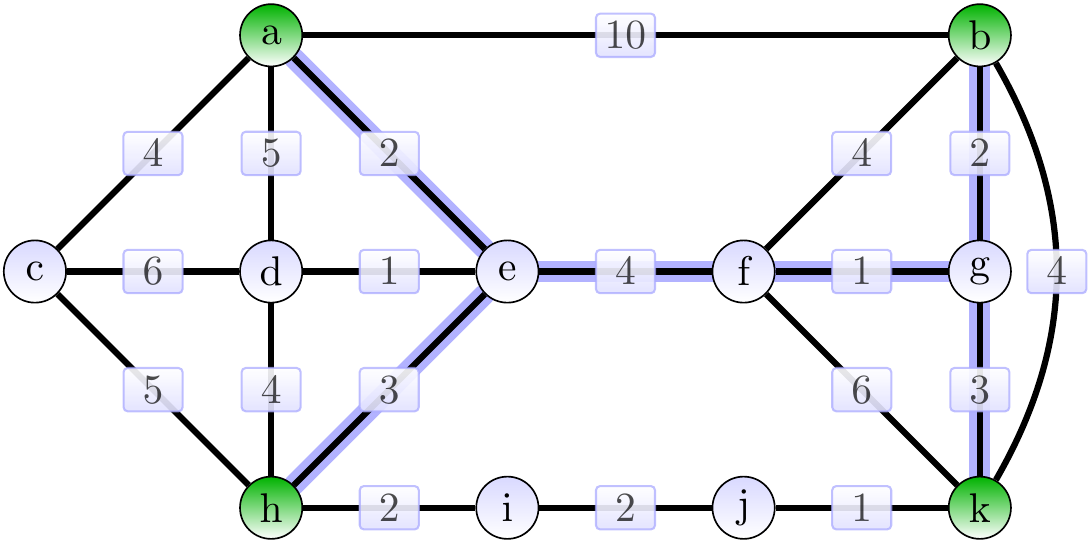
The following is a Steiner tree of weight 15.
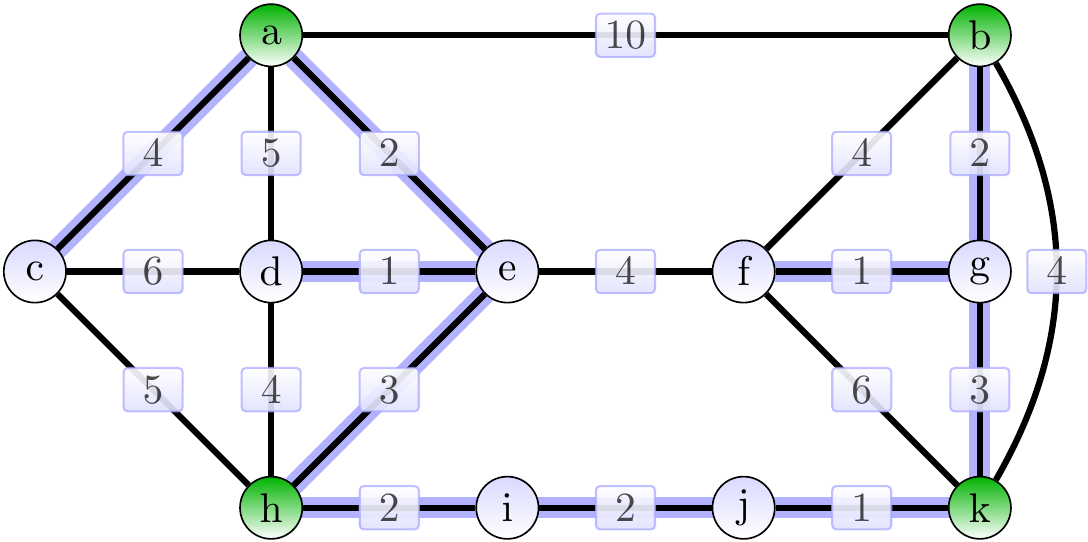
The graph below shows, in order to illustrate the difference in the problem definition, a minimum spanning tree for the graph.
As an application example, we could extend our earlier circuit board example. Now
the terminal vertices are the components,
the other vertices are crossing positions on the board through which we can draw the power/clock wires, and
the edges are the possible connections between the components and crossings.
We now want to find a minimum Steiner tree instead of a minimum spanning tree as we do not need to connect power/clock wire to each of the crossings, only the components need to be connected to each other.
Finding minimum Steiner trees is one example of an NP-hard problem. For such problems, we do not know algorithms that would have polynomial worst-case running time. There are algorithms that solve the minimum Steiner tree problem in time that is (i) exponential in the size of the terminal set \( S \) but (ii) polynomial in the size of the graph. Thus the problem is “fixed-parameter tractable”; see, for instance, this slide set. These algorithms and concepts are not included in the course exam.